Posted on: October 2, 2017 | 3 min read
The rise of business enabled analytics has come about in large part due to the failure of traditional IT to quickly respond to the ever-changing needs of the business. Data Warehouses and Operational Data Marts typically contain specific sets of data targeted to answer very specific questions for the business. They also generally have longer development cycles to prepare the data so that the specific questions can be repeatedly answered when desired by the business.
But what about the questions that the business doesn’t know they need to ask? Where do the answers to these questions come from? For most companies they go unanswered, or the business has learned to become data gymnast to contort data as part of a cumbersome weekly or monthly song and dance routine.
However, in the more recent years, there has been a quest to solve this problem for the business. The rise of Data Lakes, which are named as such due to their containment of all available data sources, both internal and external, have now given the business access to raw, untransformed data quickly. The Data Lake would contain all the sources the business is currently contorting, as well as additional sources they have never had access to before. And since the data is initially loaded straight from the source in a raw format, the business can explore and manipulate that data in their desired way until they find those hidden questions and answers.
Therefore agility is baked into Data Lakes. The business no longer needs to wait for lengthily development and QA cycles from IT before they can start answering their day to day business questions. But does that mean that development and QA activities go away? No, certainly not. The business will need to become more technical as they take on these traditional IT roles in the name of speed and agility. This is where the role of Data Engineers and Data Scientists come into play.
Data Engineers are the role type that would establish the data lake and start the initial loading of raw data. This role might sound familiar, and it should because this is not unlike the existing role of EDW Developer, combined with data modeling skills, and some Big Data Ecosystem configuration/administration.
Data Scientists are key players in the world of Big Data and Data Lakes. They are the people who know and understand the data best. They are also the people with the technical skills to produce the kind of “business-friendly” insights so desperately needed in today’s business, yet has continued to remain elusive for so long.
At a Datameer event in Atlanta, I used my time to discuss the inherent agility a Data Lake brings to a company, and how a Scrum workflow is used to organize the business needs and data ingestion workflow.
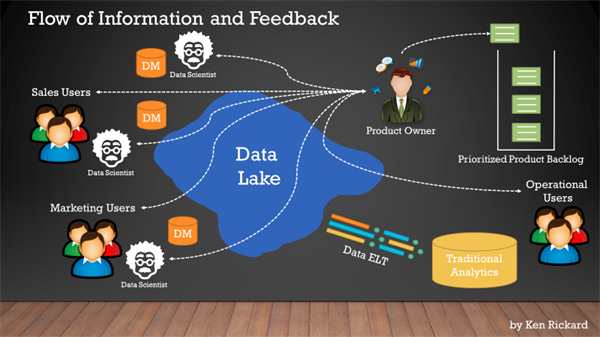
Below are some highlights of the ideas I shared:
-
Data Lakes exist to serve the data needs of the entire company quicker than traditional reporting structures
-
Data Lakes are not intended to replace traditional reporting sources such as EDWs and ODSs
-
Data Lakes can become a valuable single source for traditional reporting platforms that are intended to answer known questions repeatedly
-
Each department throughout the business can “subscribe” to any part or piece of the Data Lake to explore and create relevant insights
-
Insights discovered (explore, find patterns, formulate questions, deliver answers) might be for a single-use scenario, or they might be useful to save back into the data lake as a new set of data available for anyone to reuse
-
For initial Data Lake build out and incremental changes, use Scrum as a framework to facilitate data ingestion, delivery of raw or minimally transformed data and incorporate data lake user feedback loops (don’t flood the lake… iterate)
-
Use the Product Owner role and your Data Lake Product Backlog to ensure good communication between the IT data team and the data consumers as this is key to controlling the chaos of Big Data projects.
-
Just because the Data Lake exists doesn’t mean you’ve succeeded, you still have to create catalogs of the available data sets for easy searching, govern the creation of new data sets to ensure compliance, and secure the data to make sure only those with proper permissions see the right data. Building and maintaining these things will keep your Data Lake fresh and less like a swamp.
For more insight on how to leverage data lakes in a practical business sense, contact a data and analytics expert at (813) 265-3239 or info@ccganalytics.com.
Written by CCG, an organization in Tampa, Florida, that helps companies become more insights-driven, solve complex challenges and accelerate growth through industry-specific data and analytics solutions.
Topic(s):
Modern Data Warehouse
Return to Blog Home